Blog
Spaghetti Load: Networking Constraints in Small Servers
Introduction

Building a distributed system is all about managing dependencies. It is not only about the required software stack, processing power, or storage capacity. Network capabilities and design are just as important. But for many operators outside data centers, realistic hardware options are barely enough to enforce best practices.
A Ceph cluster can easily saturate a 1GbE interface. Proxmox nodes may have to share a single uplink for VM traffic, heartbeats, and replication. Nodes will inevitably fail at odd hours. Figuring out and documenting workarounds for these issues sometimes end up being as involved as designing for security, performance, and stability.
In this article, we are going to look at three major structural problems driving the gap between ideal networking for distributed workloads and available hardware, and how OpenSFF can help mitigate these challenges.
East-west traffic does not route itself
Data center network architecture has already shifted toward east-west traffic. In a distributed system, the most intensive communication is not between server and client. It is between nodes: VM live migrations, replication, and heartbeats and consensus messages. Cisco documented this shift well over a decade ago, and it is precisely why data centers have adopted high-bandwidth, low-oversubscription network architectures such as Spine-and-Leaf.
But such architectures assume that traffic types are physically separated. For example, an ideal Proxmox and Ceph cluster would have dedicated physical interfaces for the public network, the cluster network, Corosync, VM traffic, and management. In the small form factor and commodity space, that architecture is all but impossible. Most mini PCs have only one or two network interfaces. Those five logical networks may have to run over one physical uplink, forcing east-west traffic to share bandwidth with everything else going in and out of the system.
Without dedicated physical connections, the only option is careful VLAN design and traffic prioritization. But when the cluster comes under load, everything is still competing for the same pipe.
The NIC ceiling
The interface constraint is not just about count but also about speed. Some entry-level enterprise servers still ship with 1GbE interfaces, which we can only surmise is driven by product segmentation rather than thoughtful design. Even NAS devices, which are designed specifically to move large files, are frequently bottlenecked by CPU and NIC combinations that cannot saturate their storage.
Mini PCs with 10Gbps interfaces have become available, but those are still premium options. In addition, mini PCs offer at most a single PCIe slot in a constrained chassis. While there are M.2 NICs, they consume a slot for additional storage and may require active cooling. Thunderbolt/USB4 adapters on the other hand can run into USB generation compatibility issues and may not have equivalent drivers across platforms.
There is no multi-node SFF standard
Enterprise blade systems and OCP standards have astronomical financial, power, and cooling demands. There are no physical standards for clusters built from mini PCs or commodity servers. The 10” mini rack is a community convention with vendor variances that many businesses simply cannot tolerate. Width tolerances, screw types, and mounting adapters will inevitably vary from one system to another. Power delivery and cables add to the complexity and clutter.
This fragmentation naturally affects network design. When nodes cannot share a chassis, east-west traffic will typically go from the nodes to a cable, through an external switch and back. Cable quality, switch port configuration, and congestion all become variables that would otherwise be eliminated or contained in a properly designed internal fabric. The additional networking hardware alongside a cluster’s unique mounting, power, and port connections require careful documentation for troubleshooting and maintenance.
Full remote management is either absent or expensive
Aside from lacking a multi-node standard, small-business hardware also has no consistent management options. Intel AMT and AMD DASH offer a number of out-of-band capabilities, but both are tied to their respective chipmakers and a small subset of CPUs. Budget IP-KVM devices can be genuine game changers for some users, but they are ultimately partial solutions that may add serious cabling and security issues. As we discussed in the previous section, many users are priced out of BMCs and enterprise management platforms.
How OpenSFF can help
Our open standard directly addresses the constraints we discussed at the hardware and chassis level.
Abundant physical interfaces

Our Compute Node Specification requires Core Compute Nodes to have two Ethernet signals at 2.5GbE or faster. Enterprise Compute Nodes add another pair of 2.5GbE+ signals. Those four physical interfaces provide a modern baseline that gives operators some breathing room rather than relying mostly on VLANs. Enclosure vendors can also supplement our node requirements with additional ports.
Designed for internal switching
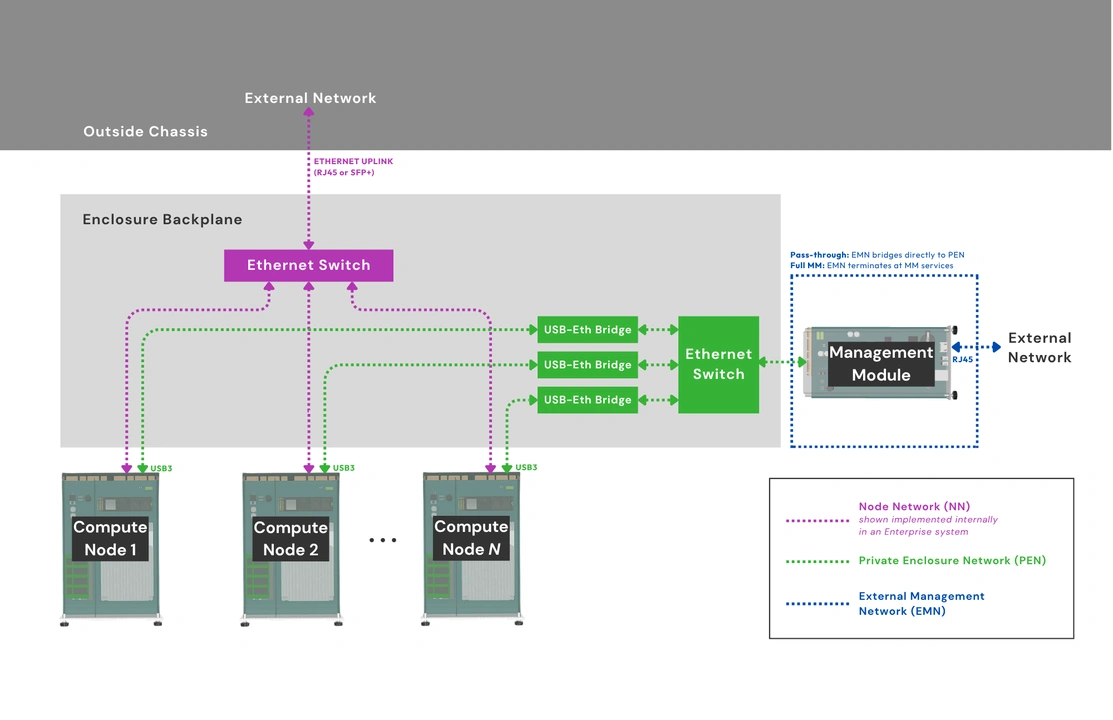
Enterprise Enclosures have a Node Network (NN), an internal Ethernet switch fabric that connects all installed Compute Nodes. Vendors will of course design this fabric around the Enclosure’s available slots. This means east-west traffic stays on short copper traces within the Enclosure rather than a shared external switch. This will reduce latency, eliminate variances from hops and cable quality, and simplify network design by consolidating a cluster’s external footprint to a few uplinks rather than one or two cables per node. Core Enclosures may also have an NN.
Standardized and affordable management platform

Our Management Module Specification defines a user-replaceable component that provides Enclosure-level KVM access and, optionally, remote management. Compute Nodes connect to the Management Module only through the Private Enclosure Network (PEN), a dedicated management network that is logically and electrically separate from the NN. As with the NN, the PEN is required in Enterprise Enclosures, but vendors are free to design Core Enclosures that also have the management network.
The Management Module has a dedicated slot in compatible Enclosures and works through an internal signal-routing infrastructure, eliminating the need to run HDMI and USB cables to each node. We have two reference designs: one is a pass-through variant for local access, and the other is a full-featured variant based on the Raspberry Pi Compute Module 5. The latter runs a custom OS based on Raspberry Pi OS and supports IP-KVM, hardware monitoring, and power management.
Modular and vendor-agnostic

Enclosures, Compute Nodes, and Management Modules from different vendors will work as one cohesive system. Even Compute Nodes with different CPU brands or architectures can work together in the same Enclosure.
Our open standard encourages vendors to provide the port counts and interface speeds that reflect modern demands and workloads. Instead of committing to a set of hardware at the point of purchase, users can instead start with an OpenSFF system that reflects their current needs and budget. They can then migrate their existing Compute Nodes to an Enclosure that has more or faster networking ports without losing their configuration or committing to a single vendor’s interface choices.

Build with OpenSFF
The computers running distributed workloads in branch-office closets, factory floors, and homelab racks deserve high quality network infrastructure just as much as enterprise systems. OpenSFF can provide users with east-west fabrics that do not compete with uplinks, enough interfaces to physically separate traffic types, and server management that does not require expensive contracts or licenses. These are not unreasonable expectations but baseline assumptions for modern distributed systems.
We encourage you to read our specifications, and we would be grateful if you spread the word about OpenSFF. For technical clarifications, partnerships, and other inquiries, reach out to our development team at [email protected].
Other Articles

Meet OpenSFF: an open hardware standard that enables cross-vendor compatibility, modular systems, and sustainable hardware reuse.
August 11, 2025

We go over the rise of virtualization and the open software adopted by home server enthusiasts, as well as the current challenges and the future of the hobby.
September 06, 2025

Learn why OpenSFF adopted the SFF-TA-1002 connector standard and how it enables our vision.
September 18, 2025